
Document management systems like the Windows Explorer or OS X’s Finder are based on real-world metaphors of files and folders. While basing a system’s conceptual model on a well-understood physical analogue creates a gentle learning curve, it limits the possibilities of abstract representation. Additionally, in order to browse documents efficiently in current file managers, users are required to create their own hierarchical relationships. Manual organization is time consuming and increasingly unrealistic now that hard drives have hundred- or thousand-gigabyte capacities.
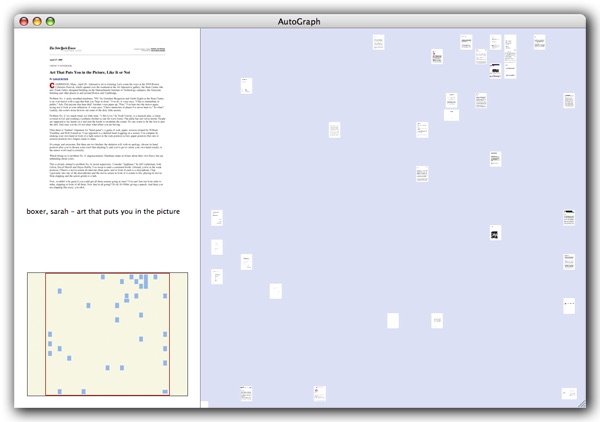
Developing a new interface for browsing a file collection requires attention to issues of categorization and representation. In this project, I focus on automatic categorization, where users aren’t required to organize their documents. The categorization system I developed uses Apple’s Search Kit indexing API to generate statistical data on text documents and uses a Kohonen Self-Organizing Map to visually cluster related documents on the screen. The self-organizing representation of the documents is designed with careful attention to aesthetics as well as functionality in order to be intuitive, simple, and powerful.
The Self-Organizing Desktop was developed as part of my senior thesis submitted to the Bard College Department of Computer Science. A PDF of the paper is available here.